2026-05-05
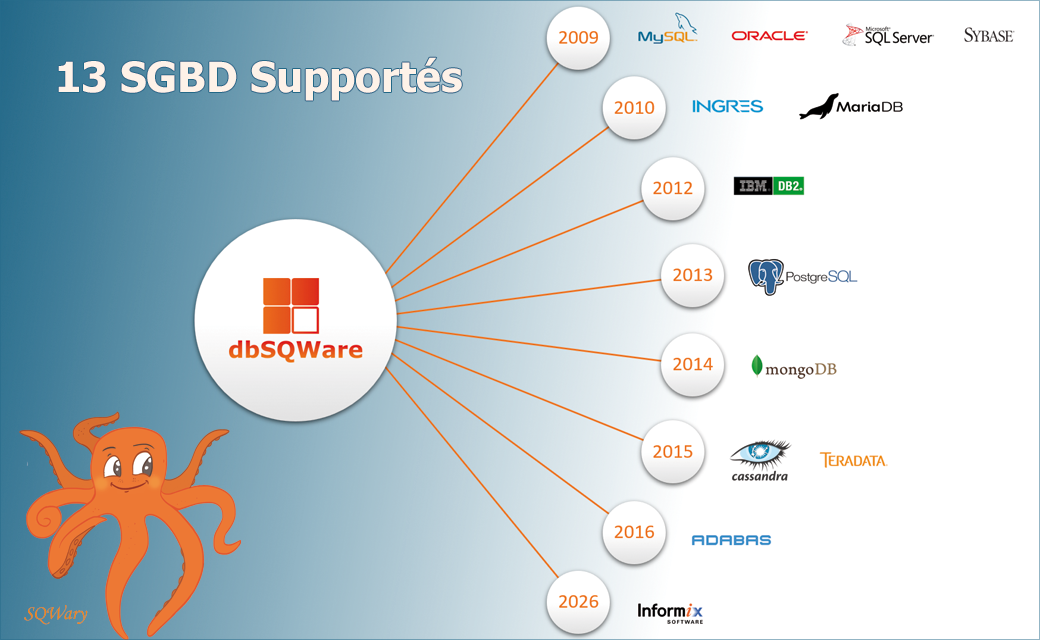
Depuis la sortie de la V2026.01 de dbSQWare, Informix fait partie des 13 SGBD supportés par le logiciel. Mais connaissez-vous Informix ? ➡️ Informix est un système de gestion de base de données relationnelle et de base de données orientée objet. Il est connu pour ses performances, sa...